지금까지 데이터와 정답이 있는 지도학습을 진행했다. 이제 정답없이 자동으로 학습을 하는 비지도학습을 익혀보자.
학습 예제로 무작위의 과일 사진모음을 자동으로 분류하기를 원하는 예제인데 타깃이 없는 상태이다.
이제 숫자가 아닌 이미지를 다루는데 어떤식으로 처리해야 할까? 정답은 픽셀이다.
픽셀 하나하나를 숫자로 치환해서 다루는게 핵심이다.
또한 본문에도 나오지만 높은 의미를 갖는 값을 흰색으로 하고 낮은 의미를 가진 값(예를 들면 바탕색)은 검은색으로 바꿔서 처리를 하면 계산이 쉽게된다.
머신러닝의 기본 작업 순서를 다시 되새겨서 크게 보면
1. 데이터 준비 및 파악
2. 적절한 전처리
3. 적절한 알고리즘으로 학습
4. 학습 평가
5. 하이퍼파라미터 조정을 통해 다시 학습 반복
6. 실제 활용
1. 데이터 준비 및 파악
캐글에 있는 300장의 과일사진을 로드하자, 이미지 높이, 넓이는 각각 100인 이미지 이므로 차원을 출력해보고
0번째 이미지의 첫번째 행을 출력해보자

자료가 흑백사진을 담고 있어서 데이터가 0~255까지의 정숫값을 가지고 있다. 좀 더 데이터를 살펴보자
첫번째 이미지는 사과인데 0에 가까울수록 검게 나타나고 높은값은 밝게 표시된다. 이 이미지는 넘파이 배열로 변환할때 반전시킨 이미지라고 한다. 흰 바탕(높은 값)은 검은색(낮은 값)으로 만들고 실제 사과가 있어 짙은 부분(낮은 값)은 밝은 색(높은 값)으로 바꾸었는데 우리가 관심있는 데이터는 사과이지 바탕이 아니므로 더 중요한 값에 높은값(흰색에 가까운)으로 만들었다. 밑에 두 이미지는 옵션을 따로 줘서 원래 이미지도 출력해보았다.
2. 적절한 전처리 및 데이터 파악
이미지라서 적절한 전처리를 하기 위해서는 100x100 이미지를 펼쳐서 1줄짜리 1차원 배열로 만들자.
그리고 요 1줄짜리 데이터 100개를 각 사과별로 평균을 내보자. 이런식으로 각 과일 개별로 평균을 내보자.
이미지 한장에 대한 평균을 내기 - 이미지 한장에 대한 점유율 비슷하게 계산되는 것과 같은 의미인데 바나나는 사진에서 차지하는 영역이 작기 때문에 평균값이 작다. 하지만 이걸로는 바나나는 쉽게 구분해낼수 있겠지만 파인애플과 사과는 평균값이 비슷하게 나오기 때문에 둘은 이렇게는 구분해내기 쉽지 않다.
그래서 전체 이미지에 대한 평균보다는 각 픽셀별 평균값을 비교하면 될듯하다.
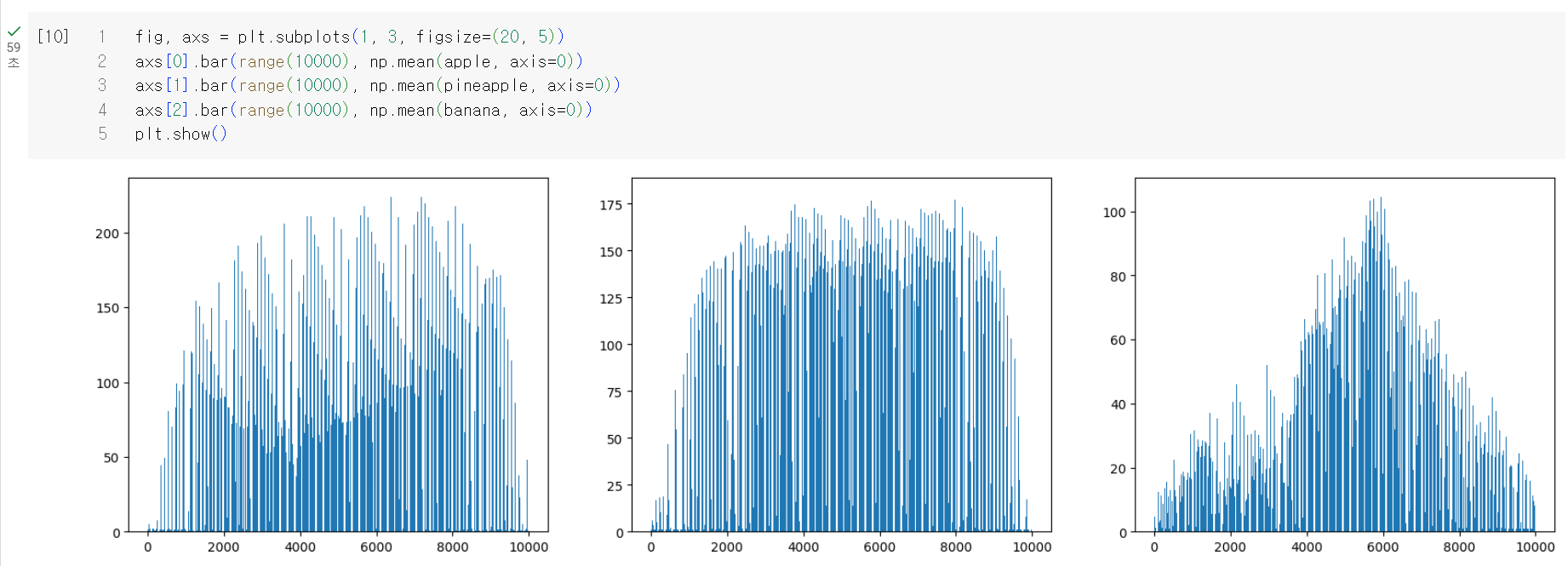
그리고 이 픽셀별 평균값을 이미지로 출력해보면 재미있는 그림이 보이는데 모든 사진을 합쳐 놓은 대표 이미지로 생각하면 될듯 하다.
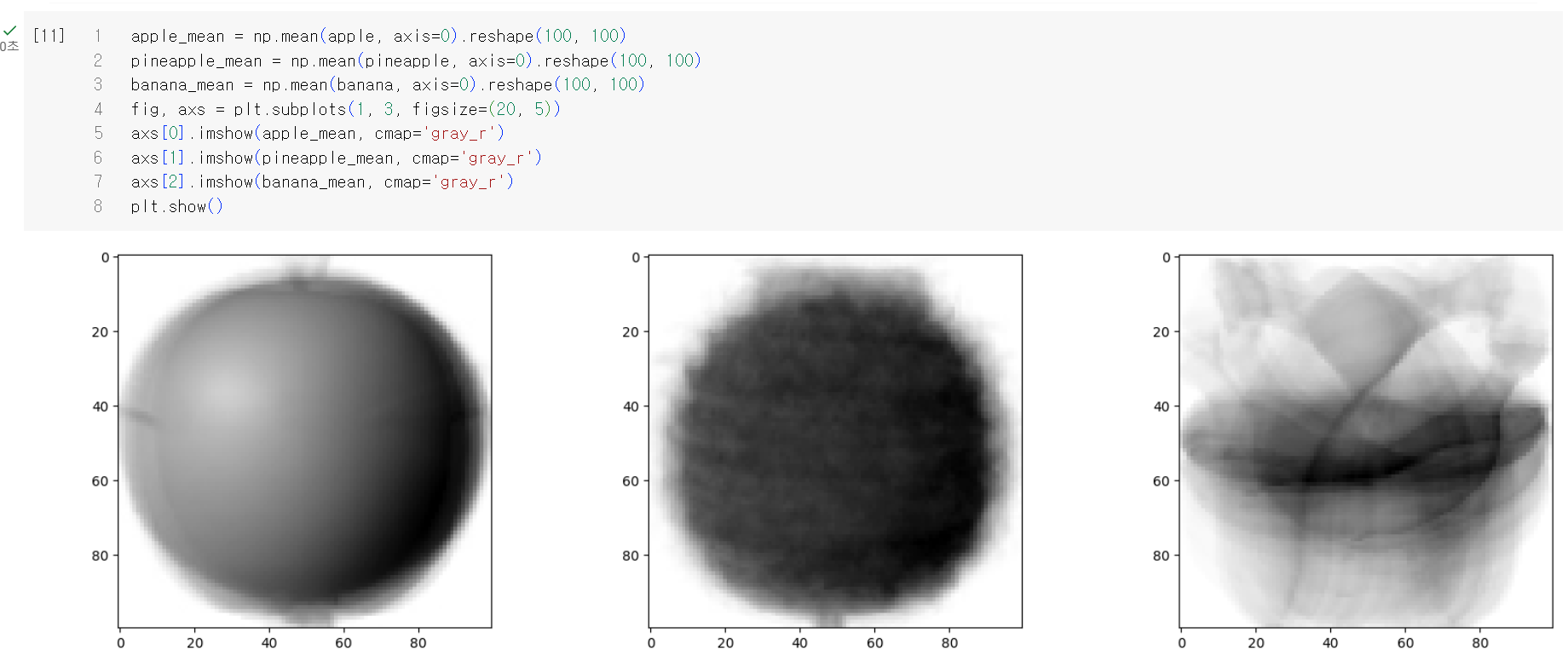
300장의 이미지중에서 그럼 저 위의 사과 평균 이미지에 가까운 이미지들만 골라보자.
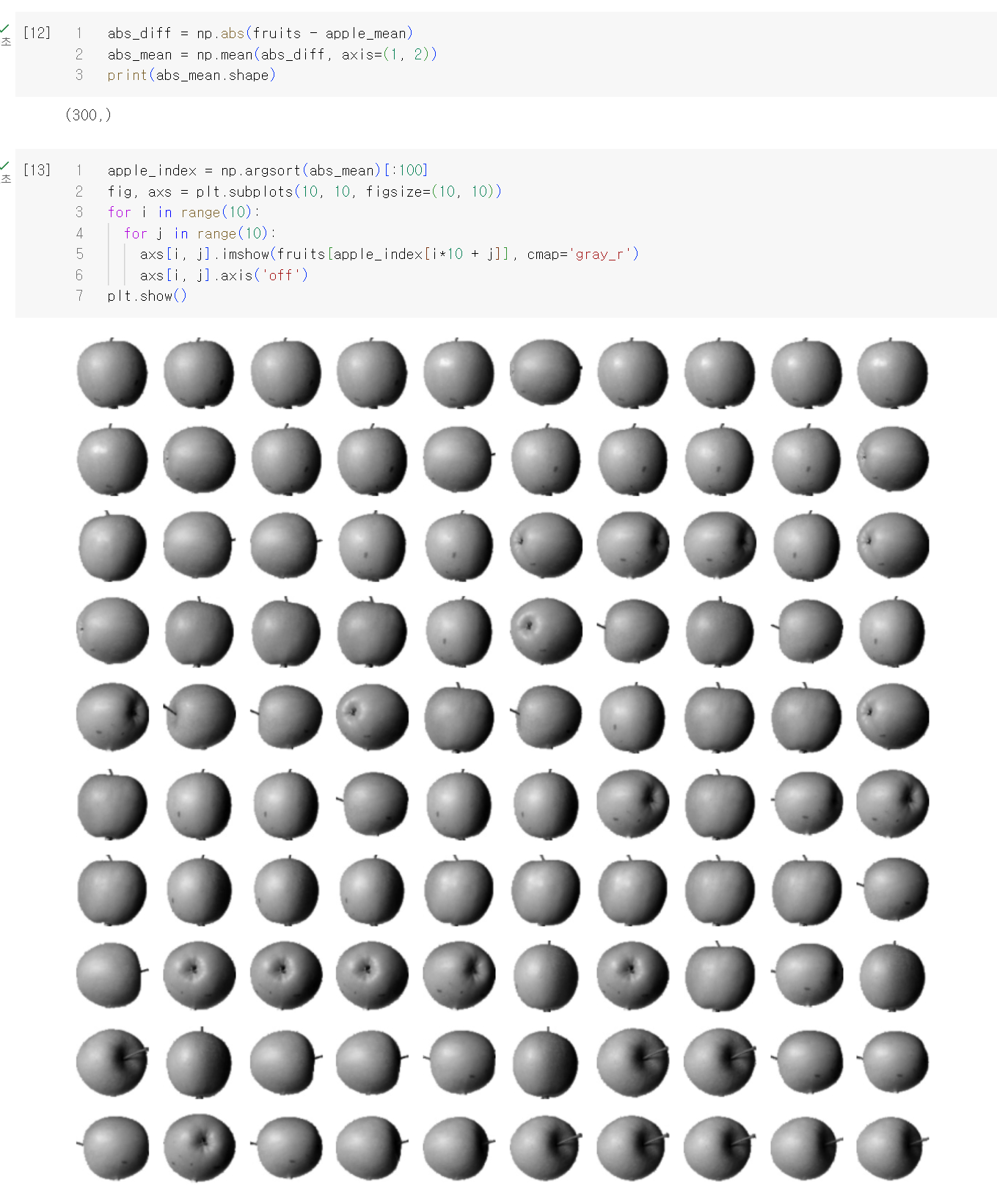
이번 챕터에서는 머신러닝 작업없이 이미지의 평균값을 찾아서 평균값에 가까운 이미지 찾는 작업을 모두 수동으로 진행했다. 다음 챕터에서는 라이브러리들을 이용해서 이 작업을 진행해보자
참조코드
#군집 알고리즘
## 과일 사진 데이터 준비하기
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
import matplotlib.pyplot as plt
fruits = np.load('fruits_300.npy')
print(fruits.shape)
print(fruits[0, 0, :])
plt.imshow(fruits[0], cmap='gray')
plt.show()
fig, axs = plt.subplots(1, 2)
axs[0].imshow(fruits[100], cmap='gray_r')
axs[1].imshow(fruits[200], cmap='gray_r')
plt.show()
apple = fruits[0:100].reshape(-1, 100*100)
pineapple = fruits[100:200].reshape(-1, 100*100)
banana = fruits[200:300].reshape(-1, 100*100)
print(apple.shape)
print(apple.mean(axis=1))
plt.hist(np.mean(apple, axis=1), alpha=0.8)
plt.hist(np.mean(pineapple, axis=1), alpha=0.8)
plt.hist(np.mean(banana, axis=1), alpha=0.8)
plt.legend(['apple', 'pineapple', 'banana'])
plt.show()
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].bar(range(10000), np.mean(apple, axis=0))
axs[1].bar(range(10000), np.mean(pineapple, axis=0))
axs[2].bar(range(10000), np.mean(banana, axis=0))
plt.show()
apple_mean = np.mean(apple, axis=0).reshape(100, 100)
pineapple_mean = np.mean(pineapple, axis=0).reshape(100, 100)
banana_mean = np.mean(banana, axis=0).reshape(100, 100)
fig, axs = plt.subplots(1, 3, figsize=(20, 5))
axs[0].imshow(apple_mean, cmap='gray_r')
axs[1].imshow(pineapple_mean, cmap='gray_r')
axs[2].imshow(banana_mean, cmap='gray_r')
plt.show()
abs_diff = np.abs(fruits - apple_mean)
abs_mean = np.mean(abs_diff, axis=(1, 2))
print(abs_mean.shape)
apple_index = np.argsort(abs_mean)[:100]
fig, axs = plt.subplots(10, 10, figsize=(10, 10))
for i in range(10):
for j in range(10):
axs[i, j].imshow(fruits[apple_index[i*10 + j]], cmap='gray_r')
axs[i, j].axis('off')
plt.show()