이제 생선 데이터를 벗어나 와인을 분류해보자.
주어진 문제는 알코올 도수, 당도, ph값으로 레드와인과 화이트와인을 분류하는 이진분류 문제이다. (화이트와인을 1로 양성 클래스)
사실 그동안의 과정을 통하면 가능한 작업이다.
와인데이터를 로드해서 데이터의 여러정보를 판다스의 기능을 이용해서 확인해보았다.

일단 데이터정보를 살펴보니 스케일이 다르기 때문에 표준화를 해야하고 데이터 안에 타겟값이 같이 들어있어 분류해내어서 써야 한다. 로지스틱 회귀를 써서 잘 분류까지 진행되는 작업이다.

하지만 위 내용은 책에서는 일반인이 계수와 절편값들이 의미하는 바를 이해하지 못하기 때문에 남들에게 좀 더 설명하기 쉬운 다른 알고리즘을 쓰는것으로 나온다. 즉 일반 순서도의 결정처리처럼 처리되게 하는 결정트리 알고리즘을 쓰게 된다.

점수는 로지스틱 회귀의 1차 시도때보다는 높게 나오는걸 볼수 있고 일단 그 처리 과정을 도식화해서 볼 수 있다는게 큰 장점인거 같다. 하지만 너무 복잡해서 일단은 설명하기 좋게 설정값등을 줄여서 출력해보자

일단 맨 위의 노드를 루트노드, 맨 아래 끝에 달린 노드를 리프노드라고 한다.
한칸 안에 표시되는 내용을 위에서부터 보면 아래처럼 표시되고 있는데
sugar < ... : 테스트 조건, 맞으면 Yes, 틀리면 No
gini = ... : 불순도
samples = ... : 이 파트에서 검사할 샘플 수
value = ... : 클래스별 샘플 수
위 설명대로 해석해보자면 맨 위에 루트 노드는 당도가 -0.239 이하인지 질문을 하고 당도가 조건값과 같거나 작으면 왼쪽가지로 감, 루트노드에서 검사한 샘플수는 5197개이고 음성클래스가 1,258개, 양성클래스가 3,939 로 해석된다.
이런식으로 계속 밑으로 진행되는 식이다. 예측하는 방법은 리프노드에서 가장 많은 클래스가 예측 클래스가 된다.
불순도
그런데 위에서 설명 안한 gini라는 수치가 있는데 이것은 지니 불순도를 의미한다고 한다. 이것은 DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값인데 노드에서 데이터를 분할할 기준을 정한다고 한다. 앞에서 당도 -0.239라는 값은 어떻게 나왔을까? 바로 criterion 매개변수에 지정한 지니 불순도를 사용한다. 그럼 지니 불순도는 어떻게 계산할까?
지니불순도는 클래스의 비율을 제곱해서 더한 다음 1에서 빼면 된다고 하는데 그게 끝!

루트노드는 총 5,197개의 샘플이 있고 그중에 1,258개가 음성, 3,939개가 양성이므로 계산하면 아래와 같다.

이때 어떤 노드의 두 클래스의 비율이 정확히 1/2씩이라면 지니 불순도는 0.5가 되어 최악이 되고, 노드에 하나의 클래스만 있다면 지니불순도는 0이 되어 가장 작다. 이런 노드를 순수 노드라고 한다. 결정트리모델은 부모노드와 자식노드의 불순도 차이가 가능한 크도록 트리를 성장시킨다.
부모노드와 자식노드의 불순도 차이를 정보이득이라고 하는데 이 알고리즘은 정보이득이 최대가 되도록 데이터를 나눈다. 이때 지니불순도를 기준으로 사용한다.
즉 노드의 테스트 조건으로는 주어진 샘풀에서 양성/음성을 골라내는 작업을 하고
노드의 불순도 값으로는 부모에서 양 자식노드로 어떻게 나눌지 정하는 기준이 되는 것이다.
가지치기
앞의 트리는 제한 없이 자라났기 때문에 훈련 세트보다 테스트 세트에서 점수가 크게 낮았는데 결정트리도 가지치기를 하지 않으면 훈련 세트에는 잘 맞겠지만 테스트 세트에서는 점수가 낮을 것이다.
결정트리에서 가지치기를 하는 가장 간단한 방법은 자라날 수 있는 트리의 최대 깊이를 지정하는 것이다.
DecisionTreeClassifier 클래스의 max_depth 매개변수를 3으로 지정해서 모델를 만들고 점수를 살펴보자.

훈련 세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로이다. 이런 모델을 트리 그래프로 그려보자.

루트노드 다음에 있는 깊이 1의 노드는 모두 당도를 기분으로 훈련세트를 나누었는데 깊이 2의 노드는 맨 왼쪽의 노드만 당도를 기준으로 나누고 왼쪽에서 두번째 노드는 알코올 도수, 나머지는 pH를 사용했다.
깊이 3에 있는 노드가 최종 노드인 리프 노드이다. 왼쪽에서 세번째에 있는 노드만 음성클래스가 더 많다 이 노드에 도착해야만 레드와인으로 예측한다.
그럼 루트에서 이 노드까지 오려면 당도는 -0.802보다 크고 -0.239보다 작으면서 알코올도수가 0.454보다 작거나 같아야 레드와인이다.
그런데 당도가 -0.802란 값은 뭔가 이상함.
앞에서 불순도를 기준으로 샘플을 나누는데 불순도는 클래스별 비율을 가지고 계산한다. 샘플을 어떤 클래스 비율로 나누는지 계산할때 특성값의 스케일이 계산에 영향을 미칠까? 아니란다. 특성값의 스케일은 결정 트리 알고리즘에 아무런 영향을 미치지 않는다고 한다. 따라서 맨위에서 특성을 표준화하지 않은 값으로 다시 훈련해보자.

전처리 한것과 점수가 같다. 역시 트리를 그려보자
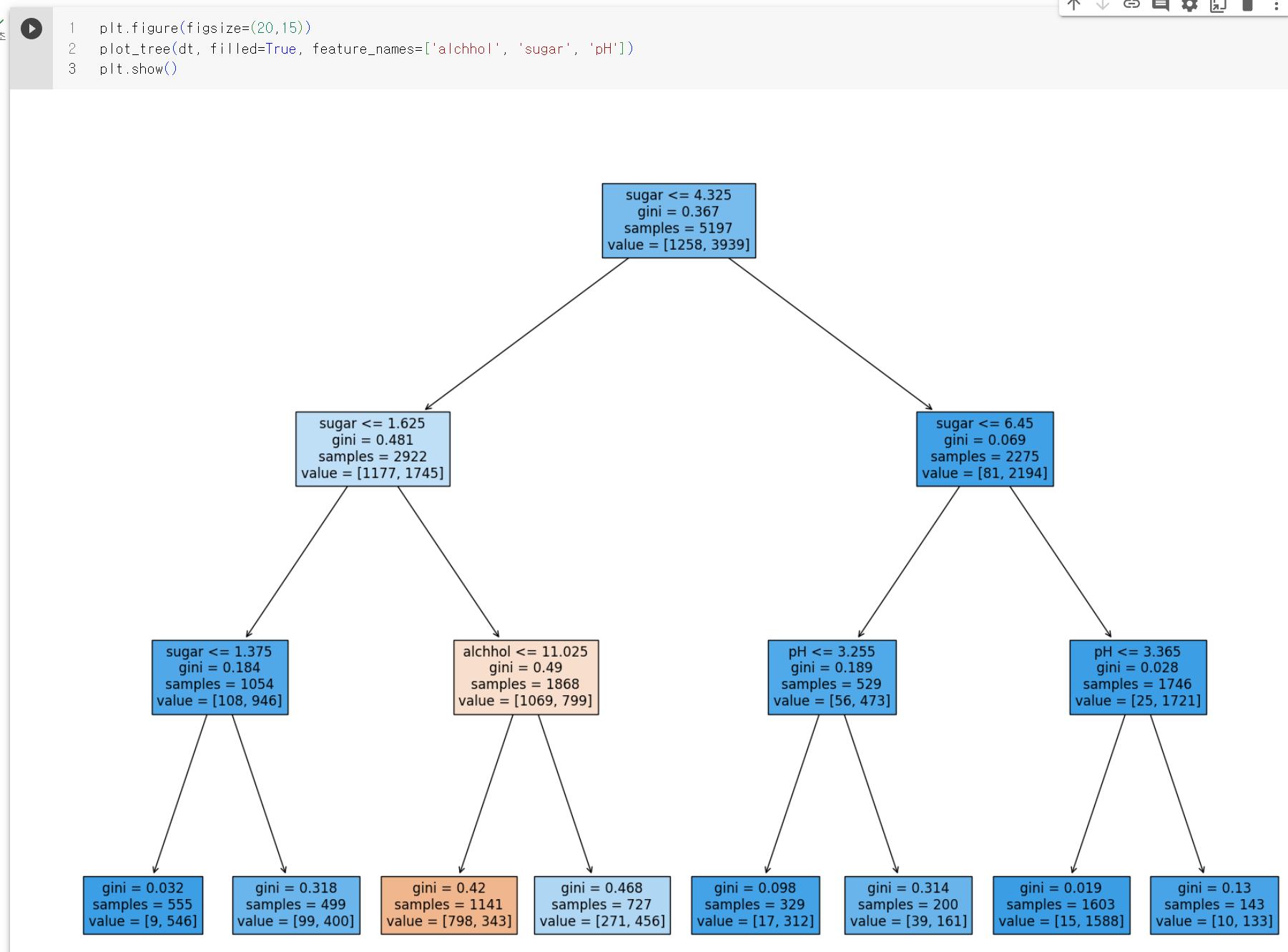
같은 트리지만 특성값이 원래 값이라 이해하기가 훨씬 쉽다.
당도가 1.625보다 크고 4.325보다 작은 와인 중에 알코올 도수가 11.025와 같거나 작은것이 레드 와인이다.
마지막으로 결정트리는 어떤 특성이 가장 유용하지 나타내는 특성 중요도를 계산해주는데 다음과 같다.

역시 두번째 특성인 당도가 0.87정도로 특성 중요도가 높게 나왔다.
이 모델은 테스트 세트의 성능이 높지 않아 화이트 와인을 골라내는 성능이 떨어지지만 제3자에게 설명하기에 아주 좋은 모델이다.