전 챕터에서는 사실 정답을 알고 있었기 때문에 정답(평균)에 가까운 사진을 찾기를 수행했었다.
하지만 진짜 비지도 학습에서는 어떤 사진이 들어있는지 알지 못한다. 이런 경우 어떻게 평균값을 구할 수 있을까?
책에선 k-평균 군집 알고리즘이 평균값을 자동으로 찾아준다고 하던데...
이 평균값이 클러스터의 중심에 위치하기 때문에 클러스터 중심 또는 센트로이드라고 불린다.
작동 알고리즘은 거리 기반 알고리즘과 비슷한데 일단 정해진 숫자만큼 그룹을 짓고 거기의 평균값을 구한다음 비교하고 좌표를 조금 이동해서 다시 정해진 숫자만큼 그룹을 짓고 평균값을 구하고 비교하고... 이런식으로 그룹내에서 변동이 없으면 종료하는 방식이다.
그럼 다시 과일사진 300개를 다시 준비하고 이 사진들을 한 평면에 쫘악 펼쳐서 배치하자 그리고 k-평균 알고리즘이 적용된 KMean 클래스로 훈련을 하자. 그리고 군집된 결과를 살펴보면

n_clusters = 3으로 지정했기 때문에 labels_ 배열의 값은 0, 1, 2 중 하나이다. 그런데 이렇게 레이블로 보는건 잘 와 닿지 않으므로 직접 이미지로 보도록 하자. 먼저 이미지로 보기전에 각 클러스터가 나타내는 이미지를 보기위해 간단한 유틸함수를 살펴보자

그리고 이 유틸 함수를 이용해서 실제 레이블 0번 모임을 출력하면

책하고 레이블 순서는 달라질수 있다고 하니 무시하고... (나머지 모음들은 책대로 사과, 바나나만 잘 모였다) 주로 파인애플 모음에 사과 9개, 바나나 2개가 포함되어 있는 모음이 나왔다. 완벽하진 않아도 타깃 데이터 없이 대체로 잘 모았다.
클러스터 중심
KMeans 클래스가 최종적으로 찾은 클러스터 중심은 cluster_centers_ 속성에 저장되어 있다. 그 중심을 이미지로 출력해보자.

전 챕터에서 출력한 평균 이미지와 비슷하다.
KMean 클래스는 훈련 데이터 샘플에서 클러스터 중심까지 거리로 변환해 주는 transform() 메소드를 가지고 있다.
인덱스가 100인 샘플에 transform() 메소드를 적용해보자

하나의 샘플을 전달했기 때문에 각 0, 1, 2 클러스터 중심까지의 거리가 나왔다. 0번째 클러스터까지의 거리가 제일 작다. 이 샘플은 0번 레이블(파인애플)에 속한거 같다. 확인해보자.

예상대로다. 실제 이미지를 출력해보자

역시 예상대로다. k-평균 알고리즘은 앞에서 설명했듯이 반복적으로 중심을 옮기면서 최적의 클러스터를 찾는데 그 반복횟수는 저장되어 있다.

여기까지 왔으면 일단 이 챕터 내용은 거의 끝난 셈이다. 그런데 사실 타깃값을 사용하지 않았지만 약간의 편법을 썼다. 그룹 갯수 n_clusters를 3으로 지정한것이다. 실전에서는 그룹갯수 조차도 알수가 없다. 그러면 최적의 n_clusters 값은 어떻게 찾아야 할까?
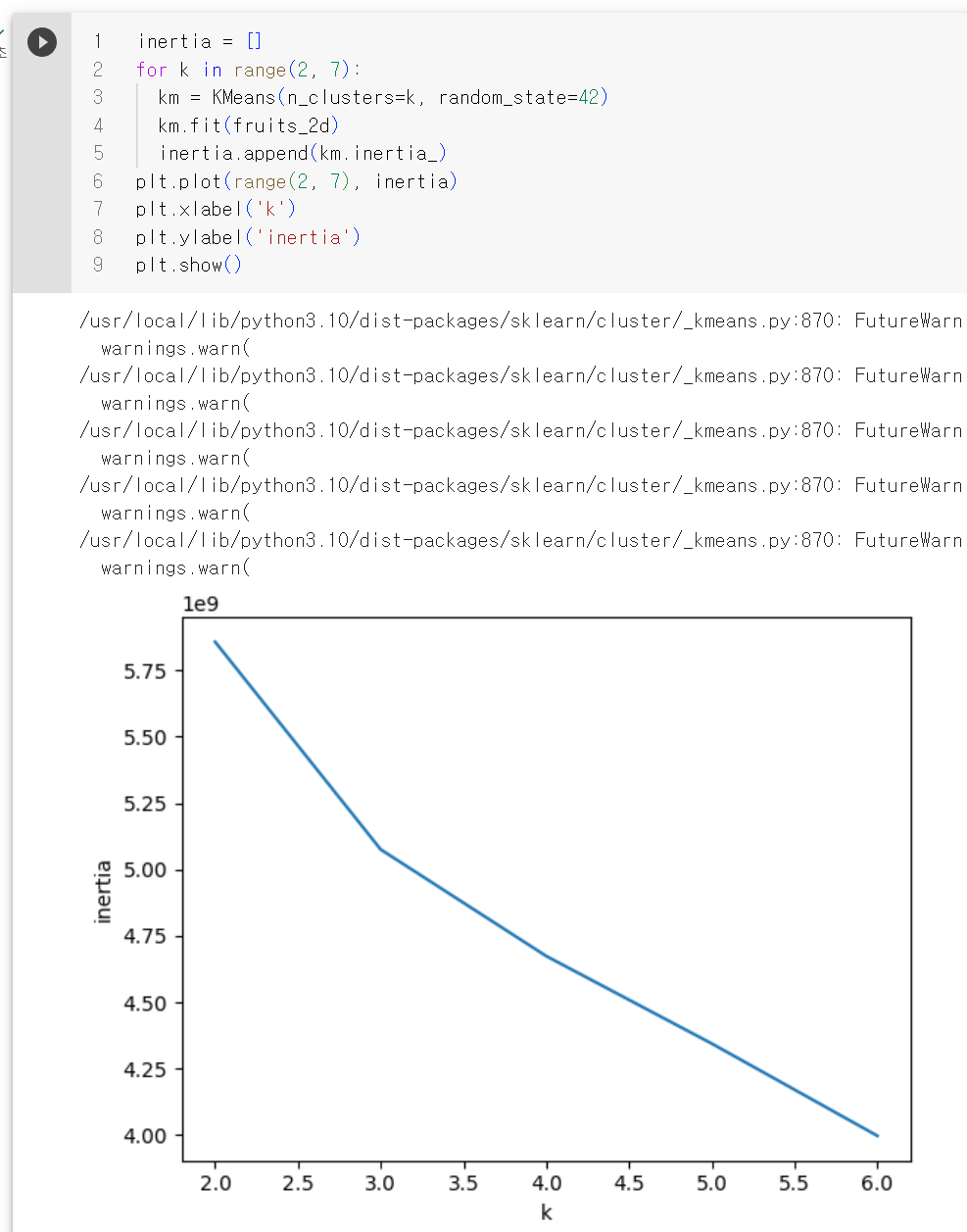
적절한 클러스터 갯수를 찾기 위한 방법으로 엘보우라는 방법이 있는데 앞에서 본 것처럼 k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있다. 이 거리의 제곱의 합을 이너셔 라고 부른다.
이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값으로 생각할 수 있다.
엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법이다.
클러스터 개수를 증가시키면서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 있는데 위 그래프에서는 3에서 그래프의 기울기가 조금 바뀐것을 볼수 있다. 그래서 최적의 클러스터 개수는 3이라는 것을 찾을수 있다.
참조코드
# K-평균
## KMeans 클래스
!wget https://bit.ly/fruits_300_data -O fruits_300.npy
import numpy as np
fruits = np.load('fruits_300.npy')
fruits_2d = fruits.reshape(-1, 100*100)
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3, random_state=42)
km.fit(fruits_2d)
print(km.labels_)
print(np.unique(km.labels_, return_counts=True))
import matplotlib.pyplot as plt
def draw_fruits(arr, ratio=1):
n = len(arr) # n은 이미지 갯수
# 한줄에 10개씩 이미지를 그린다. 샘플 개수를 10으로 나누어 전체 행 개수를 계산한다.
rows = int(np.ceil(n/10))
# 행이 1개이면 열의 개수는 샘플 개수이다. 그렇지 않으면 10개이다.
cols = n if rows < 2 else 10
fig, axs = plt.subplots(rows, cols,
figsize=(cols*ratio, rows*ratio), squeeze=False)
for i in range(rows):
for j in range(cols):
if i*10 + j < n:
axs[i, j].imshow(arr[i * 10 + j], cmap='gray_r')
axs[i, j].axis('off')
plt.show()
draw_fruits(fruits[km.labels_== 0])
draw_fruits(fruits[km.labels_== 1])
draw_fruits(fruits[km.labels_== 2])
draw_fruits(km.cluster_centers_.reshape(-1, 100, 100), ratio = 3)
print(km.transform(fruits_2d[100:101]))
print(km.predict(fruits_2d[100:101]))
draw_fruits(fruits[100:101])
print(km.n_iter_)
inertia = []
for k in range(2, 7):
km = KMeans(n_clusters=k, random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_)
plt.plot(range(2, 7), inertia)
plt.xlabel('k')
plt.ylabel('inertia')
plt.show()
k-평균 알고리즘의 작동방식 정리
1. 일단 전체 분류할 샘플(그림)을 한 공간에 펼친다.
2. 무작위로 k개의 클러스터 중심을 정한다. 이때 최적의 클러스터를 찾는 방법을 먼저 이용할수 있다.
3. 각 샘플에서 가장 가까운 클러스터 중심을 찾고 해당 클러스터의 샘플로 지정한다.
4. 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다.
5. 클러스터 중심에 변화가 없을때까지 3번으로 돌아가 반복한다.