이전 7챕터들 에서는 인공 신경망에 대해 배우고 텐서플로의 케라스 API를 사용하는 법과 1개 이상의 층을 추가하여 심층 신경망을 구성하고 다양한 고급 옵티마이저들을 알아보았다.
이렇게 딥러닝에서는 모델의 구조를 직접 만들어간다는 느낌이 훨씬 강하다.
이번 절에서는 케라스 API를 사용해 모델을 훈련하는데 필요한 도구들을 알아보겠다.
손실곡선
fit() 메소드로 모델을 훈련하면 무엇인가를 반환하는데 이때 반환값이 History 클래스 객체를 반환한다. History 객체에는 훈련과정에서 계산한 지표, 즉 손실과 정확도 값이 저장되어 있다. 이 값을 사용하면 그래프를 그릴 수 있다.
챕터를 진행하기 전에 이전의 패션 데이터를 로드하고 훈련 세트와 검증 세트로 나누자.


그리고 모델을 만드는 간단한 함수를 정의한다.

이 함수를 단순하게 호출하면 기본적으로 생성되는 모델은 이전 절과 동일한 모델이라는 것을 확인할 수 있다.
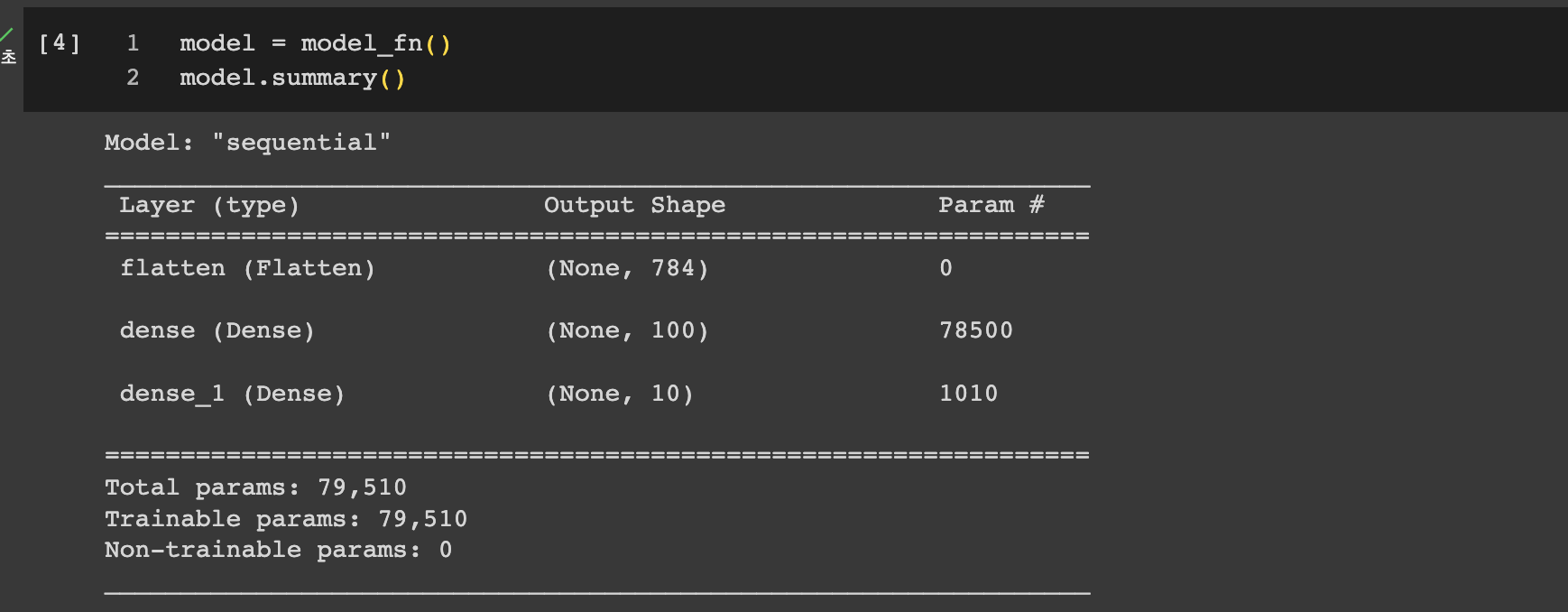
이제 fit의 훈련 결과를 담아서 출력해보도록 하자.

키값을 살펴보니 데이터에 손실과 정확도가 포함되어 있다.
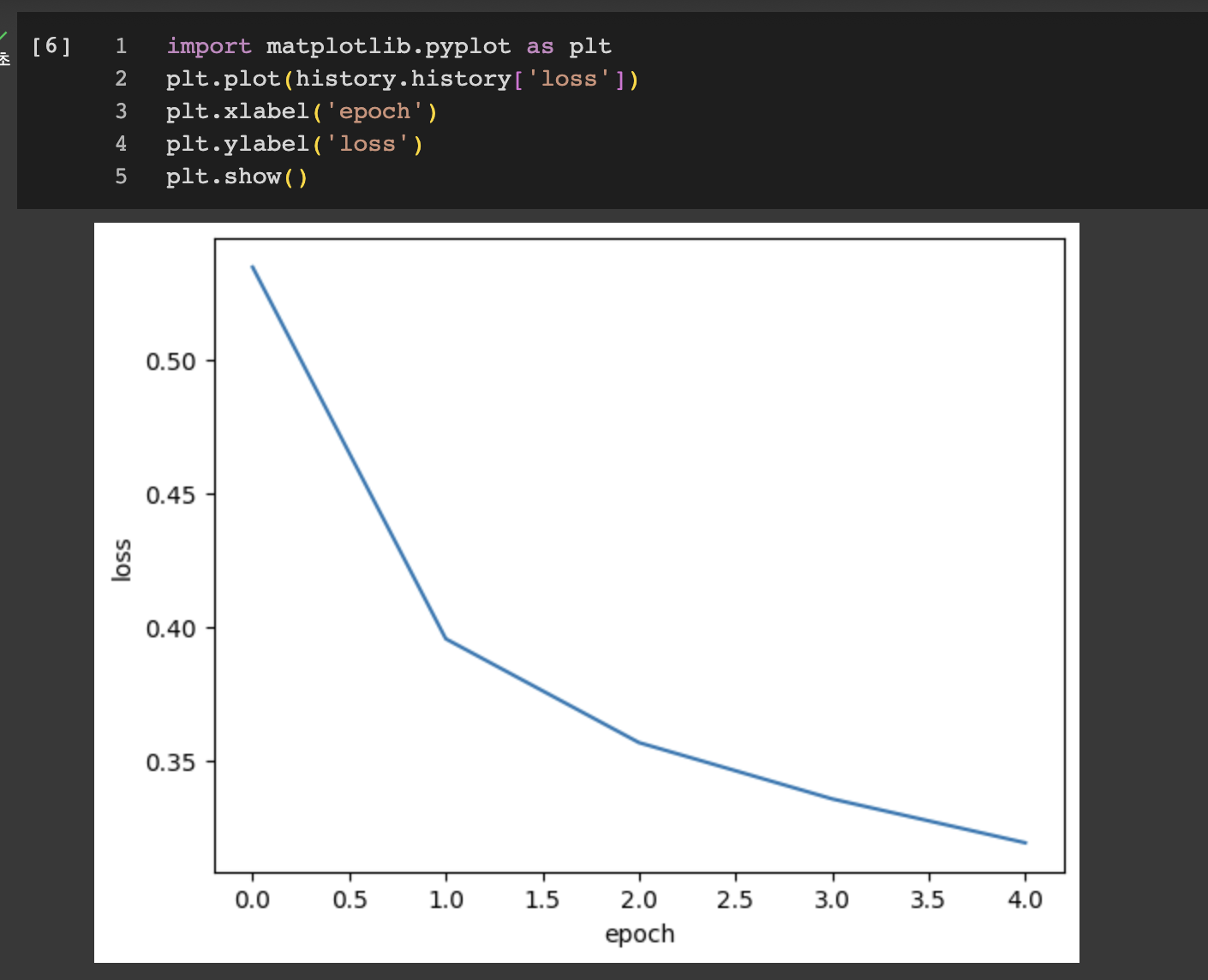
케라스는 기본적으로 에포크마다 손실을 계산한다고 하니 그걸 그래프로 나타내보면
이번엔 정확도를 출력해보면
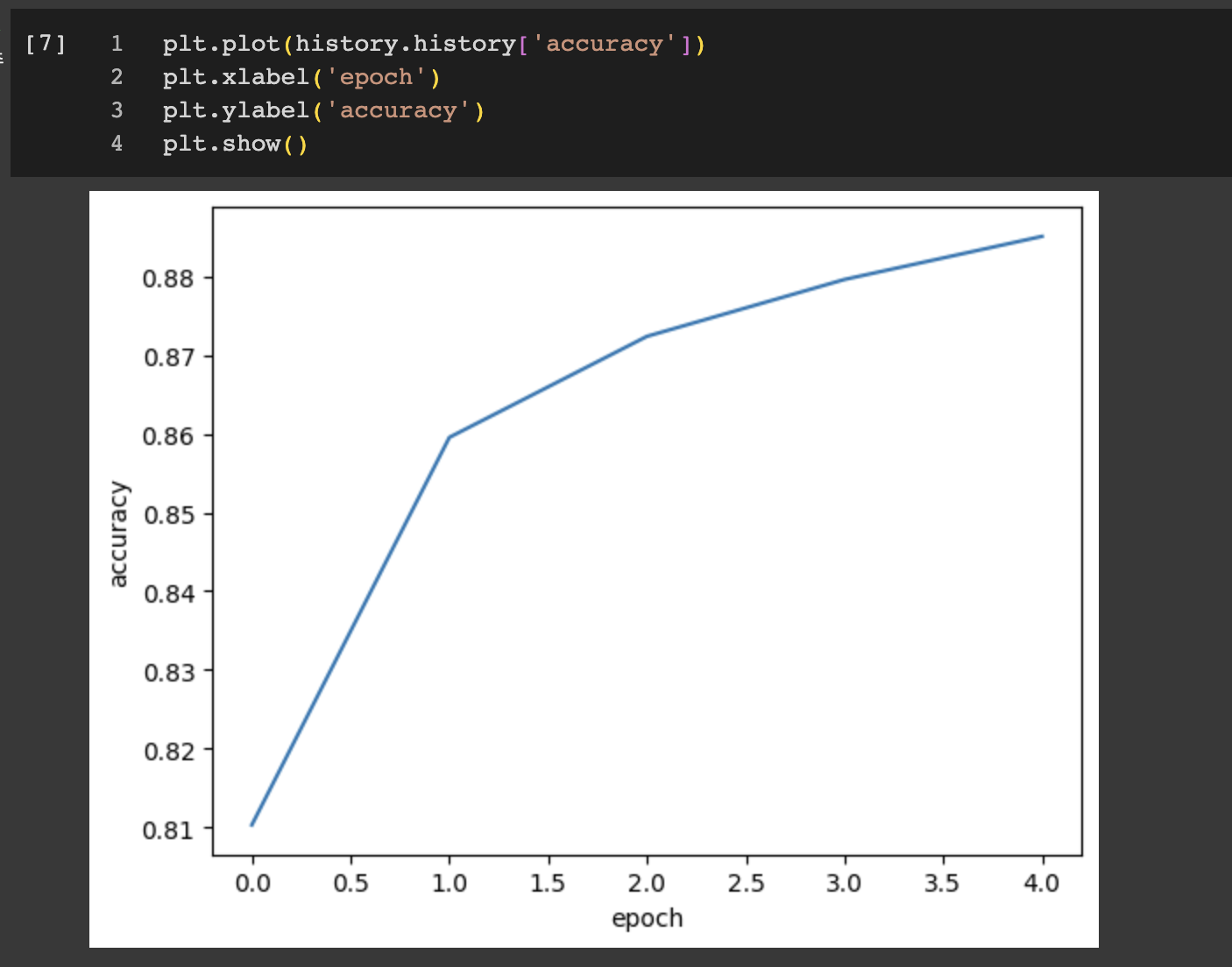
이렇게 두 그래프를 살펴보면 에포크마다 손실이 감소하고 정확도가 향상되는걸 볼 수 있다. 그럼 에포크를 늘리면 손실이 계속 감소하니까 왕창 늘려야겠네? 그래서 20번으로 늘려서 훈련하고 손실 그래프를 그려보았다.
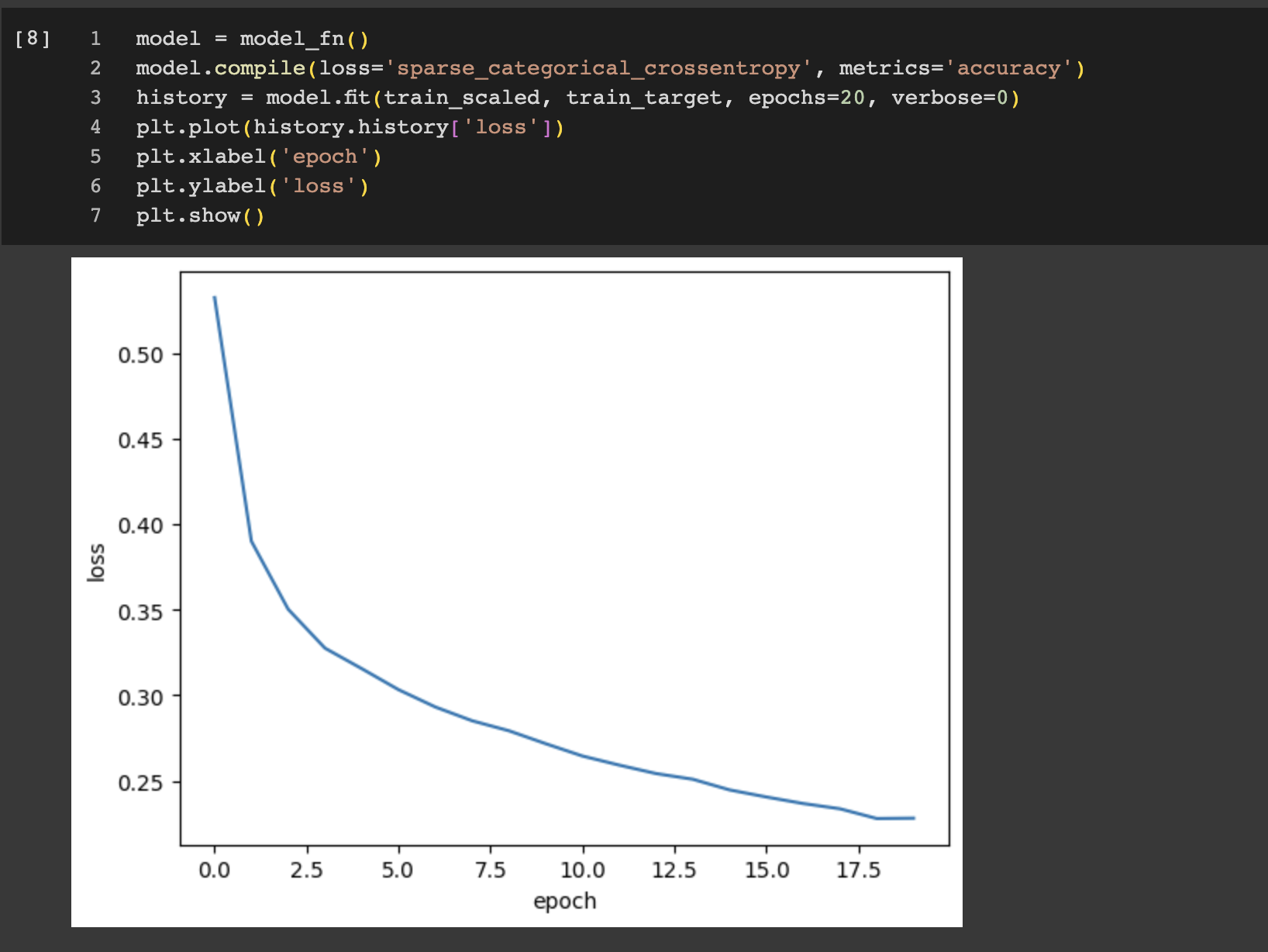
검증손실
인공신경망은 모두 일종의 경사 하강법을 사용하기 때문에 에포크가 증가할수록 점점 좋아지는걸 알 수 있다.
에포크에 따른 과대/과소 적합을 제대로 파악하려면 훈련세트에 대한 점수 뿐만 아니라 검증 세트에 대한 점수도 필요하다. 따라서 앞에서 처럼 훈련 세트의 손실만 그려서는 안되고 검증 세트에 대해 그래프도 같이 그려봐야 한다.
그러기 위해서는 fit 훈련시 검증데이터도 같이 세팅해야 한다.

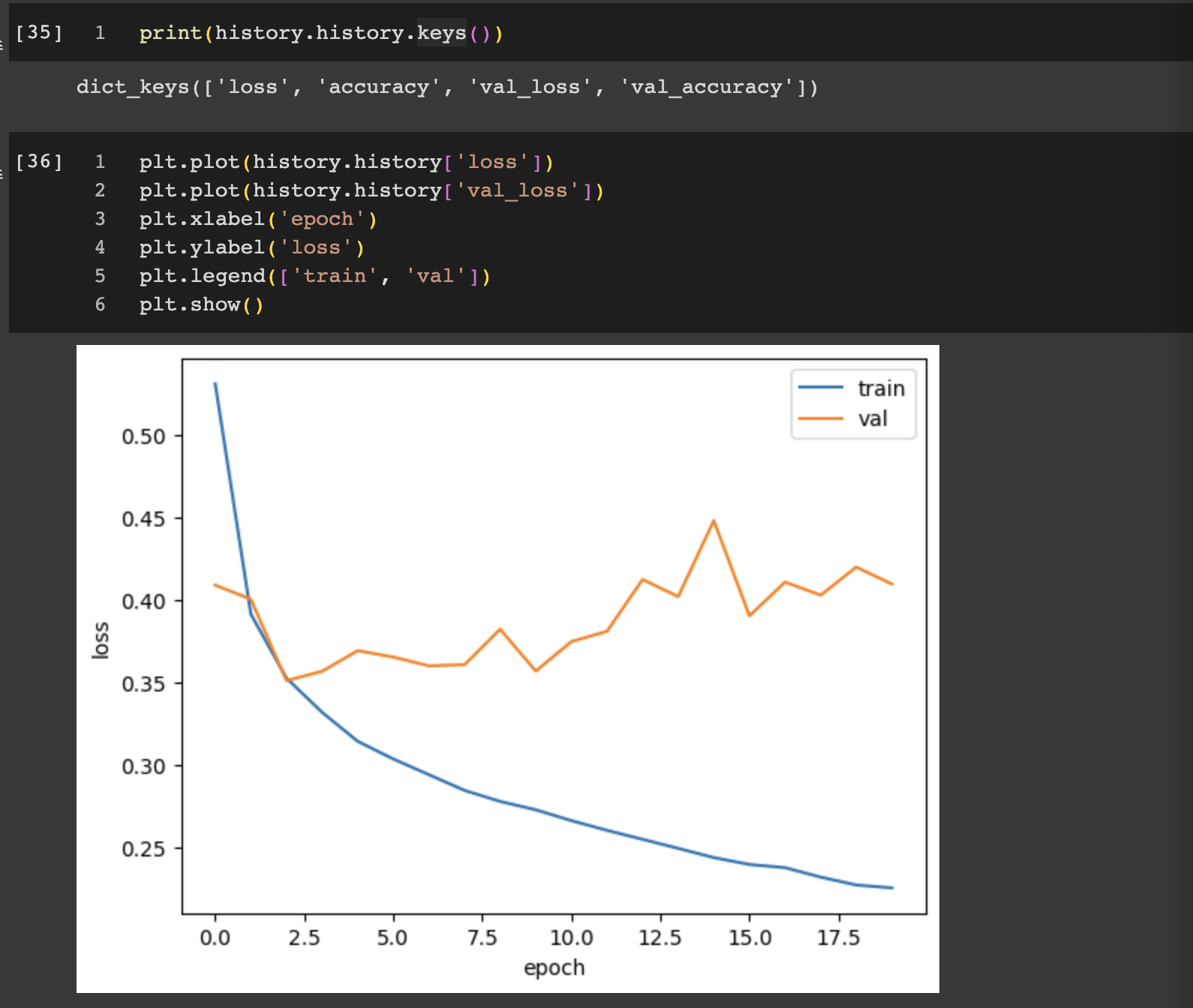
반환된 값을 보면 검증 세트에 대한 손실은 val_loss에 들어 있고 정확도는 val_accuracy에 들어 있다. 훈련 세트와 검증 세트의 추세를 동시에 같이 그려보면 검증 손실이 에포크 8정도 쯤에서 감소하다가 다시 상승하는걸 볼 수 있다. 훈련 손실은 꾸준히 감소하기 때문에 전형적인 과대적합 모델이 만들어진다. 검증 손실이 상승하는 시점을 가능한 뒤로 늦추면 검증 세트에 대한 손실이 줄어들 뿐만 아니라 검증 세트에 대한 정확도도 증가할 것이다.
또한 기본 옵티마이저인 RMSProp 대신 다른 옵티마이저를 테스트해서 결과를 살펴보는 것도 나쁘지 않을 것이다. 밑의 모델은 Adam 옵티마이저를 적용해 보고 그래프를 그려본것이다.
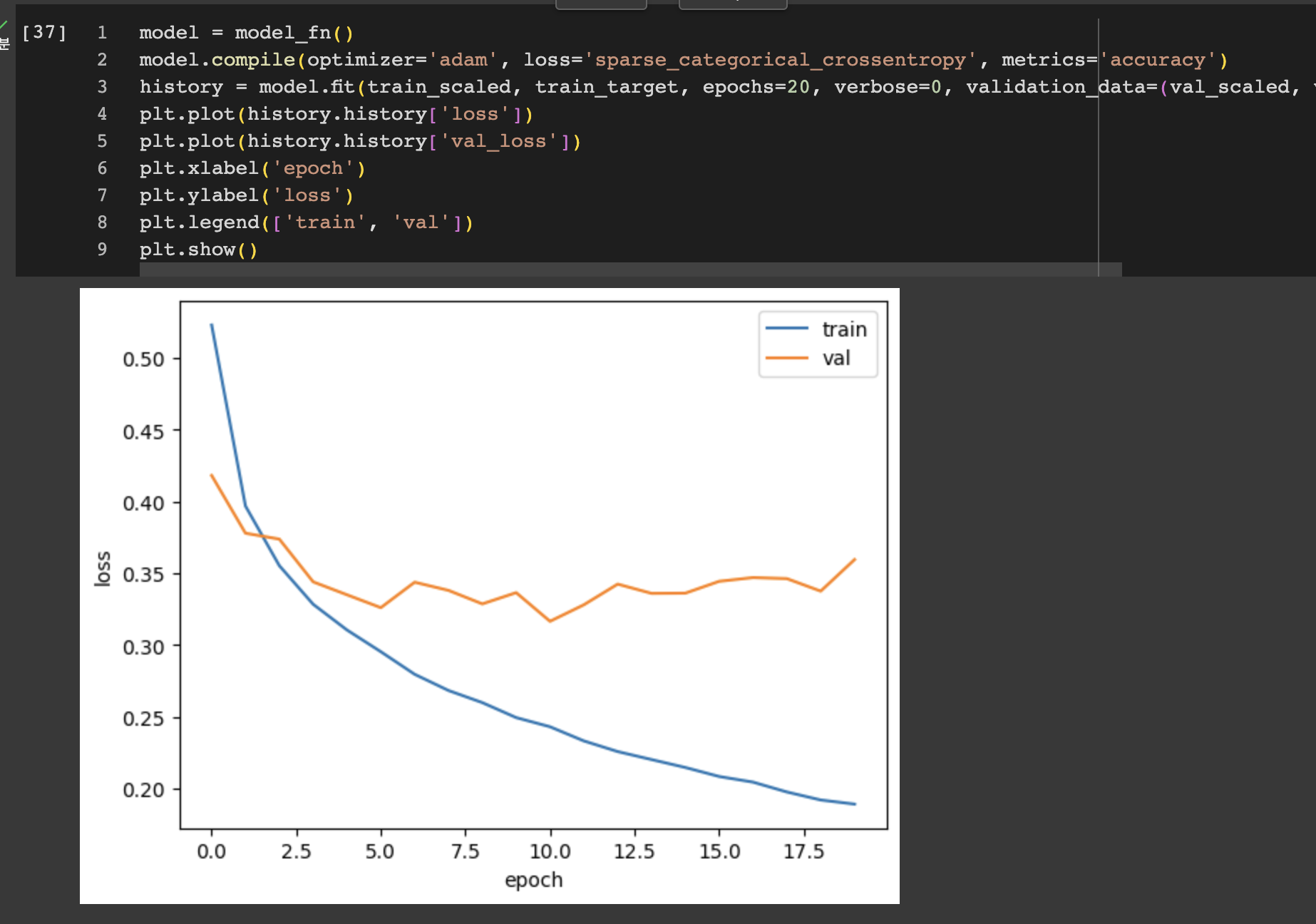
과대 적합이 훨씬 줄어든걸 알 수 있다. 이는 Adam 옵티마이저가 이 데이터셋에 잘 맞는다는 것을 보여준다.
이렇게 옵티마이저 하이퍼파라미터 조정만으로 성능 향상을 기대할수 있다.
드롭아웃
드롭아웃은 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 과대적합을 막는다.
드롭아웃은 어떻게 과대 적합을 막는가? 이전 층의 일부 뉴런이 랜덤하게 꺼지면 특정 뉴런에 과대하게 의존하는 것을 줄일 수 있고 모든 입력에 대해 주의를 기울여야 한다. 일부 뉴런의 출력이 없을 수 있다는 것을 감안하면 이 신경망은 더 안정적인 예측을 만들 수 있을 것이다.
케라스에서는 드롭아웃을 Dropout 클래스로 제공하는데 어떤 층의 뒤에 드롭아웃을 두어 이 층의 출력을 랜덤하게 0으로 만드는 것이다.
그럼 드롭아웃을 30% 정도를 적용한 모델을 만들어 보자.

이 모델로 그래프를 그려보면
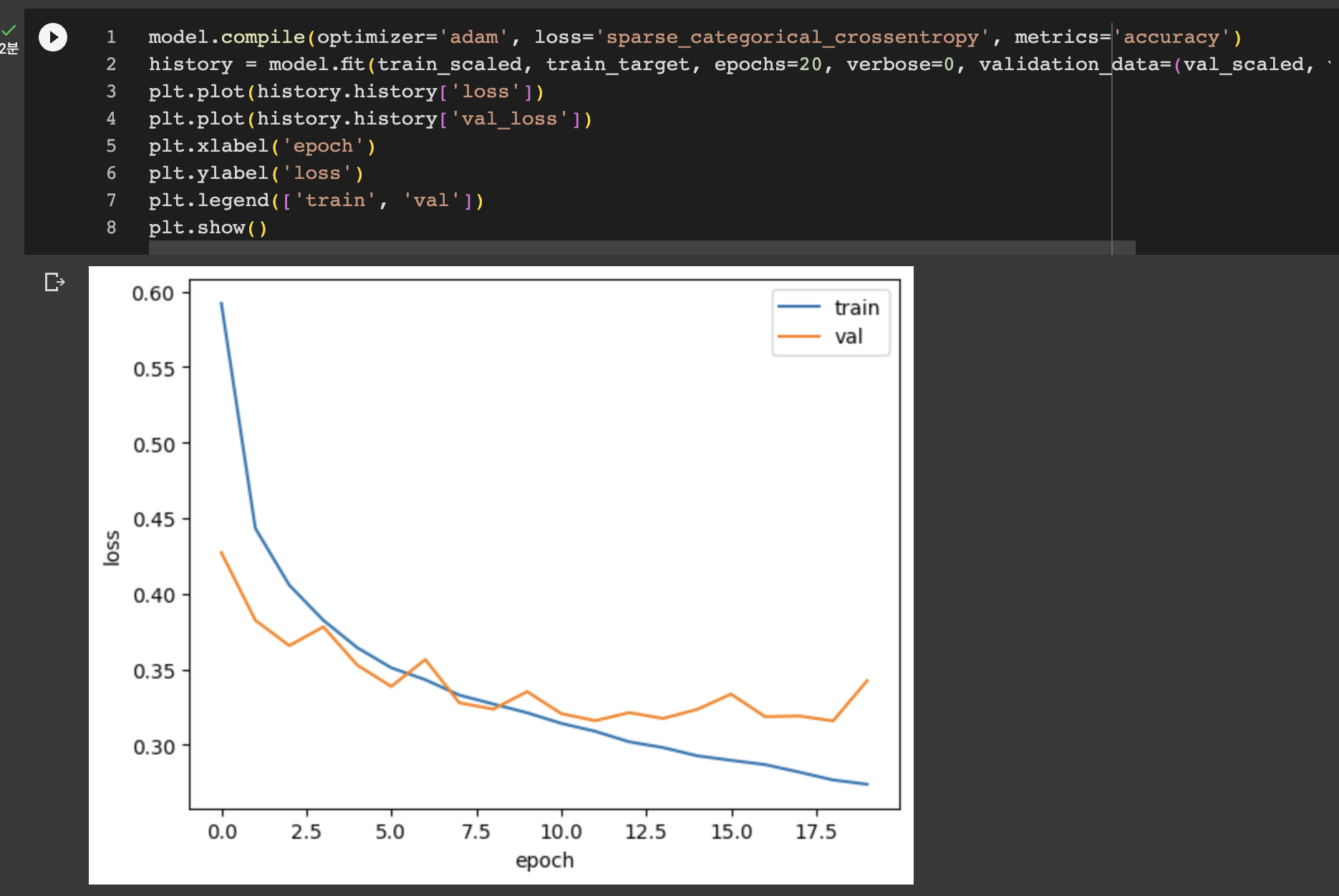
확실히 과대 적합이 줄어든걸 알수 있다. 열번째 에포크 정도에서 검증 손실의 감소가 멈추기 때문에 에포크 횟수를 10으로 하고 다시 훈련해야 한다.
모델 저장과 복원
에포크 횟수를 10으로 다시 지정하고 훈련을 하는데 나중에 다시 사용하려면 이 모델을 저장해야 한다.
케라스 모델은 훈련된 모델의 파라미터를 저장하는 save_weights() 메서드를 제공한다. 또한 모델 구조와 모델 파라미터를 함께 저장하는 save() 메서드도 제공한다.
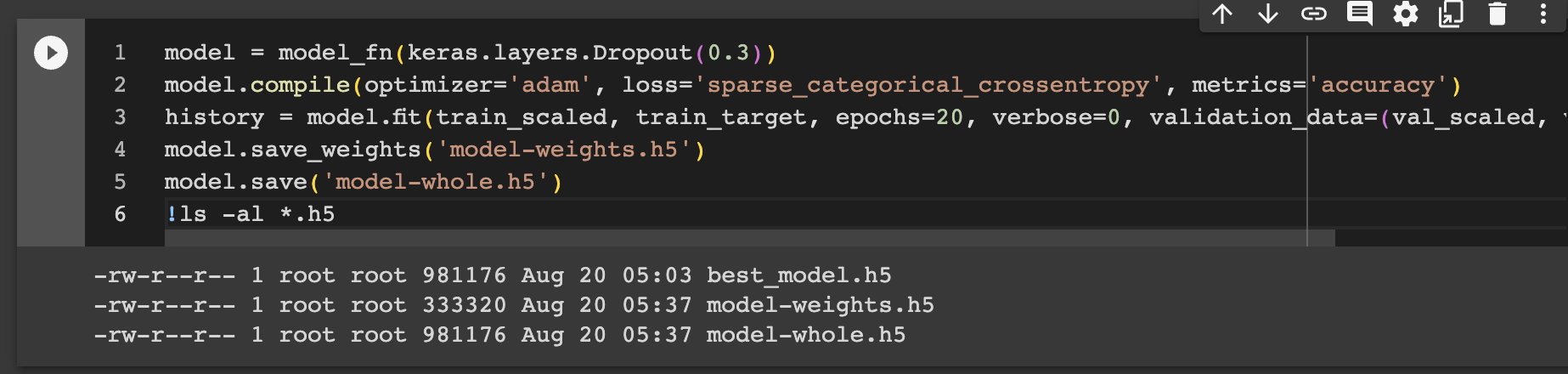
이렇게 저장된 파일을 검증하기 위해 먼저 훈련하지 않은 모델을 만들고 파라메터만 로드해서 적재해서 사용하는것과 전체 모델 구조와 파라미터를 로드해서 저장과 로드가 제대로 되는지 확인해보자
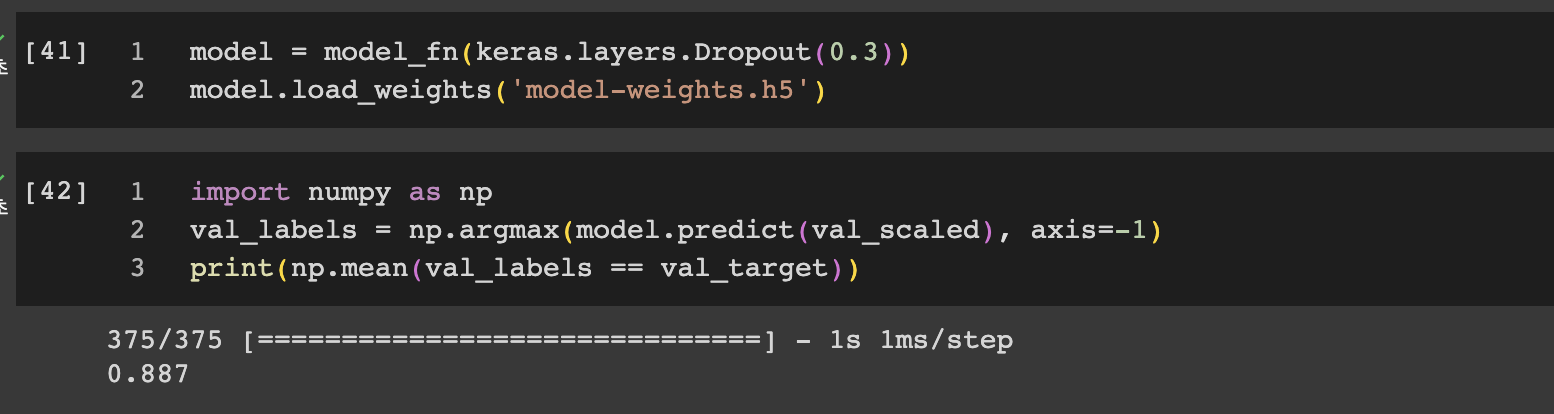
load_weights로 저장해놓은 model-weights.h5를 로드해서 검증 데이터를 예측해보자.
사이킷런과 달리 케라스는 샘플마다 10개의 클래스에 대한 확률을 반환한다. 패션 MNIST 데이터셋이 10개에 대한 다중 분류 문제이기 때문이다. 0.887이 나온걸 알수 있다.
이제 모델 전체를 로드해서 검증 세트의 정확도를 출력해보자.

역시 위와 동일한 0.887이 나온걸 볼 수 있다. 그런데 이 과정을 살펴보면 처음에는 에포크는 20번이라는걸 임시로 정해서 훈련했었고 검증 점수가 상승하는 지점을 확인한다음 과대적합 되지 않는 에포크만큼 다시 훈련했다. 이렇게 두번씩 훈련하지 않고 한번에 끝내기 위해 케라스의 콜백 기능을 사용할 차례다
콜백
콜백은 훈련 과정 중간에 어떤 작업을 수행할 수 있게 하는 객체로 여기서 사용할 ModelCheckpoint 콜백은 기본적으로 최상의 검증 점수를 만드는 모델을 저장한다. 저장될 파일 이름을 best-model.h5로 지정하여 콜백을 적용해보자
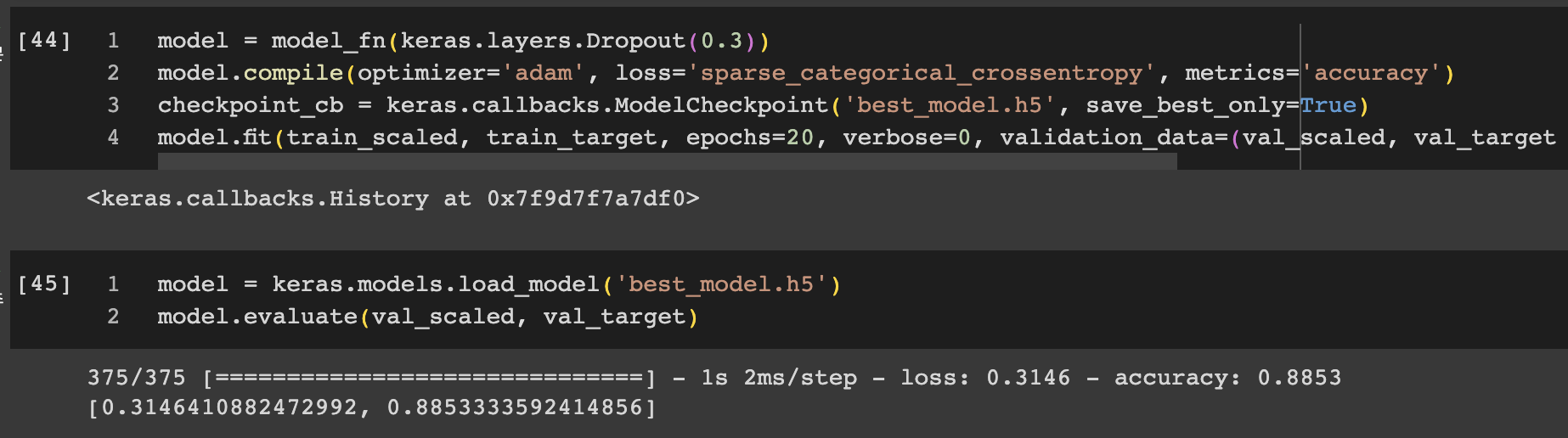
모델을 훈련한 후에 best-model.h5에 최상의 검증 점수를 낸 모델이 저장된다. 이 모델을 load_model() 함수로 다시 읽어서 예측을 수행해보면 훨씬 편하게 작업할 수 있다. 하지만 여전히 에포크값은 20번을 세팅해놓은 상태이다.
검증 점수가 상승하기 시작하면 그 이후에는 과대 적합이 더 커지기 때문에 훈련을 계속할 필요가 없다. 이때 훈련을 중지하면 컴퓨터 자원과 시간을 아낄 수 있다. 이렇게 과대적합이 시작되기 전에 훈련을 미리 중지하는 것을 조기 종료라고 부르고
케라스에서는 조기 종료를 위한 EarlyStopping 콜백을 제공한다.
EarlyStopping 콜백을 ModelCheckpoint 콜백과 함께 사용하면 가장 낮은 검증 손실의 모델을 파일에 저장하고 검증 손실이 다시 상승할 때 훈련을 중지할 수 있다. 또한 훈련을 중지한 다음 현재 모델의 파라미터를 최상의 파라미터로 되돌린다.
사용해보자

훈련을 마치고 몇 번째 에포크에서 훈련이 중지되었는지 확인할 수 있는데 나는 7번이라고 나온다. 훈련 손실과 검증 손실을 출력해서 확인해보자
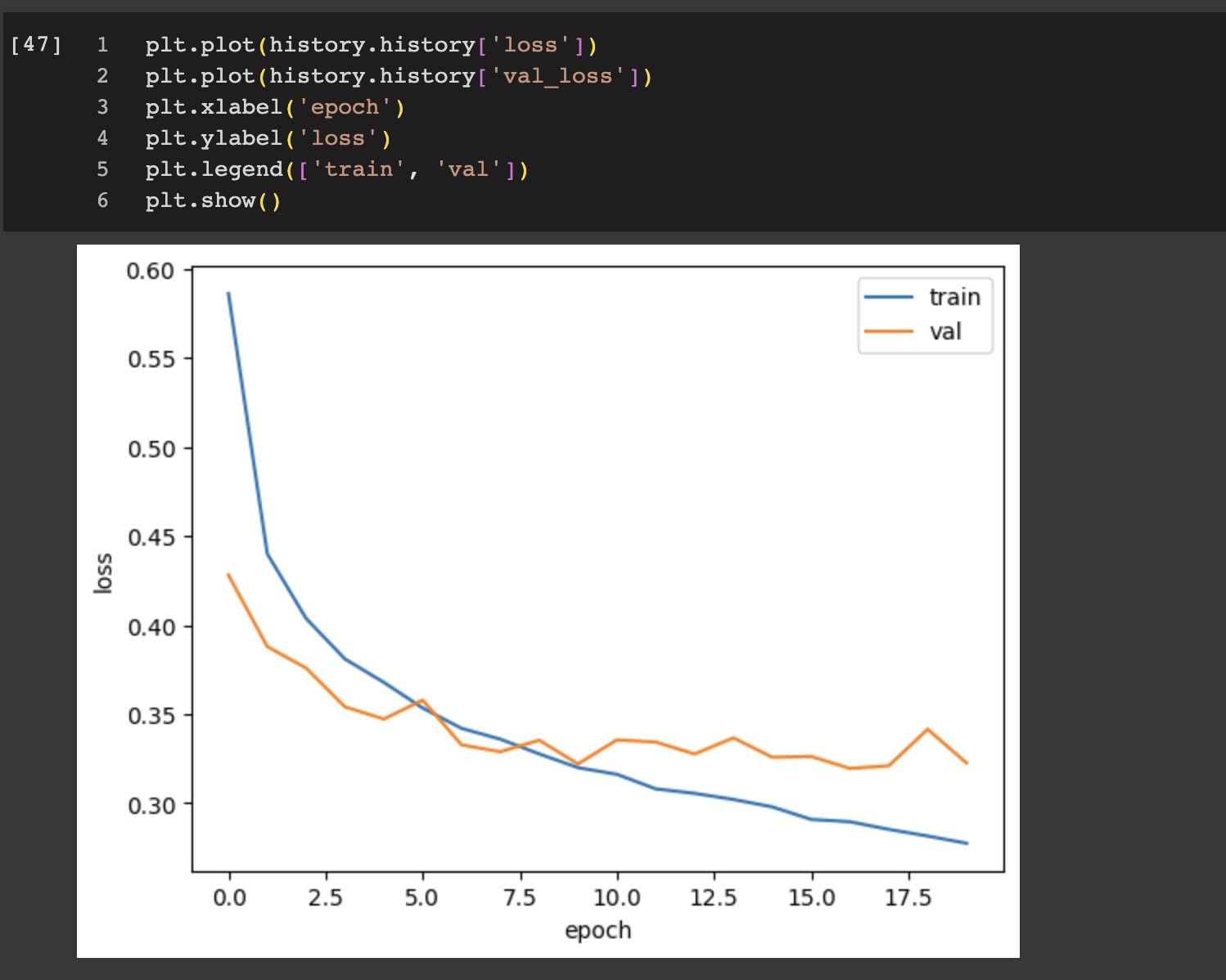
조기 종료로 얻은 모델을 사용해 검증 세트에 대한 성능을 확인해보자

참고로 위의 결과는 모두 코랩 CPU상태에서 훈련했던거고 TPU 상태에서 훈련한 값이랑 크게 차이 나지는 않았다.
참고코드
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation='softmax'))
return model
model = model_fn()
model.summary()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
print(history.history.keys())
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
plt.plot(history.history['accuracy'])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0)
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
model = model_fn()
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target))
print(history.history.keys())
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
model = model_fn()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
model.save_weights('model-weights.h5')
model.save('model-whole.h5')
!ls -al *.h5
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weights.h5')
import numpy as np
val_labels = np.argmax(model.predict(val_scaled), axis=-1)
print(np.mean(val_labels == val_target))
model = keras.models.load_model('model-whole.h5')
model.evaluate(val_scaled, val_target)
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best_model.h5', save_best_only=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb])
model = keras.models.load_model('best_model.h5')
model.evaluate(val_scaled, val_target)
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best_model.h5', save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb])
print(early_stopping_cb.stopped_epoch)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
model.evaluate(val_scaled, val_target)'AI > 혼자 공부하는 머신러닝+딥러닝 책' 카테고리의 다른 글
| 혼공학습단 10기(혼자 공부하는 머신러닝)를 끝내면서.... (0) | 2023.08.23 |
|---|---|
| 챕터 07 - 2 (4) | 2023.08.19 |
| 챕터 07 - 1 (0) | 2023.08.11 |
| 챕터 06 - 3 (0) | 2023.08.05 |
| 챕터 06 - 2 (4) | 2023.08.04 |