챕터 2 : Stable Diffusion WebUI의 기초와 활용, 스카이 박스 환경맵 제작하기
를 살펴보도록 하자.
책에 자세히 나와 있으므로 내가 차이점을 찾아볼때 바로 직관적으로 알수 있도록 풀어서 적어보자.
체크포인트 모델 : 이미지 특성 모델 선택 (예를 들면 실사풍이냐 일본 애니풍이냐등을 선택)
크게 3가지가 있다. 베이스 모델, 체크포인트, 확장모델
베이스 모델 : 기본 모델이라고 보면 된다.
체크포인트 : 용도에 맞게 커스터마이징 된것이 체크포인트이다. ckpt 또는 safetensors 확장자로 되어 있는데 기존 ckpt 형식에서 개선된게 safetensors 이다.
확장모델 : 체크포인트에 추가로 다른 학습모델을 붙이는 개념이다. 체크포인트에 헬멧이라는 개념이 없다면 헬멧이 학습된 확장모델을 붙여 인물에 헬멧을 씌울 수 있게 된다. 대표적인게 LoRa, Hyper Networks이다.
긍정 프롬프트 : 이미지 생성 방향
부정 프롬프트 : 이미지가 피해야 할 요소
Sampling method :
스테이블 디퓨젼이 노이즈를 추가하거나 삭제를 하면서 작업을 해 나가는 방식인데 해당 노이즈를 어떤 방식으로 적용할지 정하는 부분
샘플링에 관한 자세한 설명은 여기를 참고하자.
요약하면
- Euler a : 일반적, 고전적인 샘플러 - 기본 세팅
- DPM++ 2M Karras : 속도도 빠르고 성능도 좋음
- DPM++ SDE Karras : 디테일이 좋지만 이미지 생성 속도가 조금 느림
등이 있는데 이밖에도 상당히 많은 샘플러가 있다.
Sampling steps :
위에서 정한 노이즈를 몇번까지 적용할지 정하는 부분
최소 20회가 필요하다. 이미지가 좋지 않으면 일단 좀 더 늘려볼 수 있다. 40회 이상은 거의 필요가 없다고 한다.
Hires. fix :
기본적인 생성은 저해상도도 작업을 하고 생성이후에 퀄리티업을 위한 곳이다. 생성시에 과도한 세팅을 하면 시간도 많이 걸리고 자칫하면 이미지 생성도 실패할수 있다.
Width / Height :
출력 이미지의 크기. 512x512가 기본이다. 텍스트 프롬프트가 동일할 경우에도, 크기가 달라지면 생성되는 이미지가 엄청나게 달라진다. 예를 들어 이미지 크기는 좌우가 넓은데 서있는 사람을 프롬프트에 입력해서는 생성될 확률이 떨어진다. 이때는 512x768 등 landscape가 아닌 portrait 크기로 지정하는 것이 좋다. 이미지 크기를 잘못 설정하면 기괴한 이미지가 생성될 수도 있다.
Batch count / size :
이미지 생성 개수를 설정, count는 이미지 생성을 반복하는 횟수, size는 한번에 생성하는 이미지 개수를 의미한다.
CFG Scale :
AI가 프롬프트 내용을 얼마나 참고할지 설정하는 기능. 값이 낮을 수록 AI가 자율적으로 해석. 값이 너무 높으면 프롬프트 그대로만 나옴. 4.5 ~ 10 사이에서 조정 6.5값을 많이 사용
Seed :
-1로 지정하면 무작위로 지정된다. 모든 이미지에는 시드 값이 있다고 생각하면 되는데, 동일한 값을 입력하면 동일한 이미지를 얻을 수 있다.
Script :
외부 확장 기능을 설치하는 곳이다.
Clip skip :
각 모델마다 권장되는 설정 중에 Clip skip이라는 파라메터 값이 존재한다. 이 설정은 체크포인트에 학습된 텍스트를 어느정도의 구체성으로 해석할 것인지를 결정하는 값이다. 스디의 세팅값에서 설정할수 있다.
전페이지의 내용하고 이번 세팅을 적용해서 책의 내용을 재현해보자. (체크포인트는 기본으로)
Prompt :
(master piece:1.2), best quality, highly detailed, Carne Griffiths, key visual, concept art, (a black cat:1.0), sharp focus, profile icon
Negative prompt:
blurry, low quality, croped, human, error, lowers, bad anatomy, ugly
Steps: 40, Sampler: Euler a, CFG scale: 8.5, Seed: 1007478874, Size: 512x512, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Version: v1.8.0

세팅값과 시드값을 맞추니 거의 비슷한 이미지가 생성되는걸 알수 있다. 이로써 적절한 세팅값과 프롬프트 값을 찾고 저장해두면 작업의 연속성을 가질수 있을거 같다.
이 챕터에서 쓰이는 체크 포인트를 살펴보자.
AbyssOrangeMix3 모델 검색시 후방주의 하시고 ㅎㅎ (한번에 검색이 안될수 있다. 걍 구글 검색하면 된다.)
DreamShaper는 8버전까지 나온거 같은데 일단 책대로 4 baked vae로 받자.
BreakDomain_m2000 는 정확히 맞는 모델이 없어 breakdomain 기본모델을 받았다.

같은 프롬프트인데 dreamshaper로 작업한것이다.

OrangeMix3로 바꾼거 (Clip skip 2)

OrangeMix3로 바꾼거 (Clip skip 1) 레이어에 따른 차이도 이렇게 크니 꼭 알아둬야 겠다. Clip 1은 텍스트에 영향을 받는 인물위주라면 2는 뭔가 원래 텍스트 위주로 하려는 경향이 있는거 같다.

책에선 VAE 옵션에 관해서도 설명을 해주는데 생성된 이미지의 색감과 선명도를 개선해주는 후보정용 모델이라고 한다. VAE는 다른 모델과 다르게 이미지 구조에 영향을 주지 않는다고 함.
VAE설명은 여기가 잘되어 있다.
vae-ft-mse-84000
kl-f8-anime2
anything-v3.0
여기까지 작업하면서 느끼는건 세팅값과 프롬프트값들은 잘 적어놓아야 한다는 것이다. 뭔가 모델변경이나 UI변경때마다. 세팅값과 프롬프트값이 날아가면 슬슬 짜증난다.
그래서 Setting > User Interface > Infotext 항목에 보면
Create a text file ~ 이런 항목을 체크해 두면 이미지 생성할때 마다 쌍으로 세팅값으로 텍스트 파일로 같이 생성한다.
프롬프트 :
(masterpiece, 4k ,ultra detailed:1.2),(beautiful face:1.2),(anime:1.2),illustration,(realistic:1), (1girl:1.5), (solo:1.5), (looking at viewer:1.4), (standing:1.2),(supermodel:1.4),(full body:1.2),(hands inside pocket:1.2), (simple background,red background, abstract:1.3), (scarlet off-shoulder jacket), (t-shirt,tight three quarter pants:1.2), (violet hair, colored inner hair),(long length ponytail hair)
부정 프롬프트:
blurry, (worst quality, low quality:1.4), (loli,child), man, boy, croped, error, lowers, bad anatomy, ugly, (text:1.3), watermark, name, logo
Steps: 30, Sampler: DDIM, CFG scale: 7, Seed: 2143324885, Size: 512x768, Clip skip: 2, Hires fix: Latent, Hires steps: 15, Denoising strength: 0.6, Upscale by: 1.5
VAE는 None

VAE는 kl-f8-anime2 인 상태 확실히 색감도 진하고 애니풍이다.

Extra Networks(확장모델)
확장 모델은 체크포인트에 없는 데이터를 주입시키거나 프롬프트만으로 제어하지 못하는 부분을 가능하게 해준다고 함.
대표적인 확장 모델은 LoRA, Texual Inversion(Embedding), Hyper networks 3가지가 있다고 함.
LoRA
추가로 LoRA 및 확장 모델을 사용할 때 체크포인트 모델과 Base Model 버전이 일치해야 한다고 함.
책에 나온대로 Urban samurai를 적용해서 의상만 바꿔보자.
LoRA 세팅과 관련해서 자세한 내용은 여기 참조
음 SD 1.5인데 괜찮을까? 난 1.8 해당 폴더에 모델을 넣었는데 화투패는 안보이고 Lora탭에서는 보여서 선택후 생성
흠... 분위기는 비슷하게 나온거 같은데 너무 깨져보인다. 책을 다시 자세히 보니 가중치라는 값이 있다고 한다.
<lora:urbansamuraiv3testing:1>

가중치 값을 좀 낮췄더니 꽤 그럴싸 하다.
<lora:urbansamuraiv3testing:0.7>

조금더 낮췄봤다.
<lora:urbansamuraiv3testing:0.5>

ㅎㅎ 이제는 영향을 살짝 받은 정도로 나온다. 이제 LoRA는 꺼주고 img2img기능의 inpaint 기능을 써보자. 상의만 마스킹을 했다.
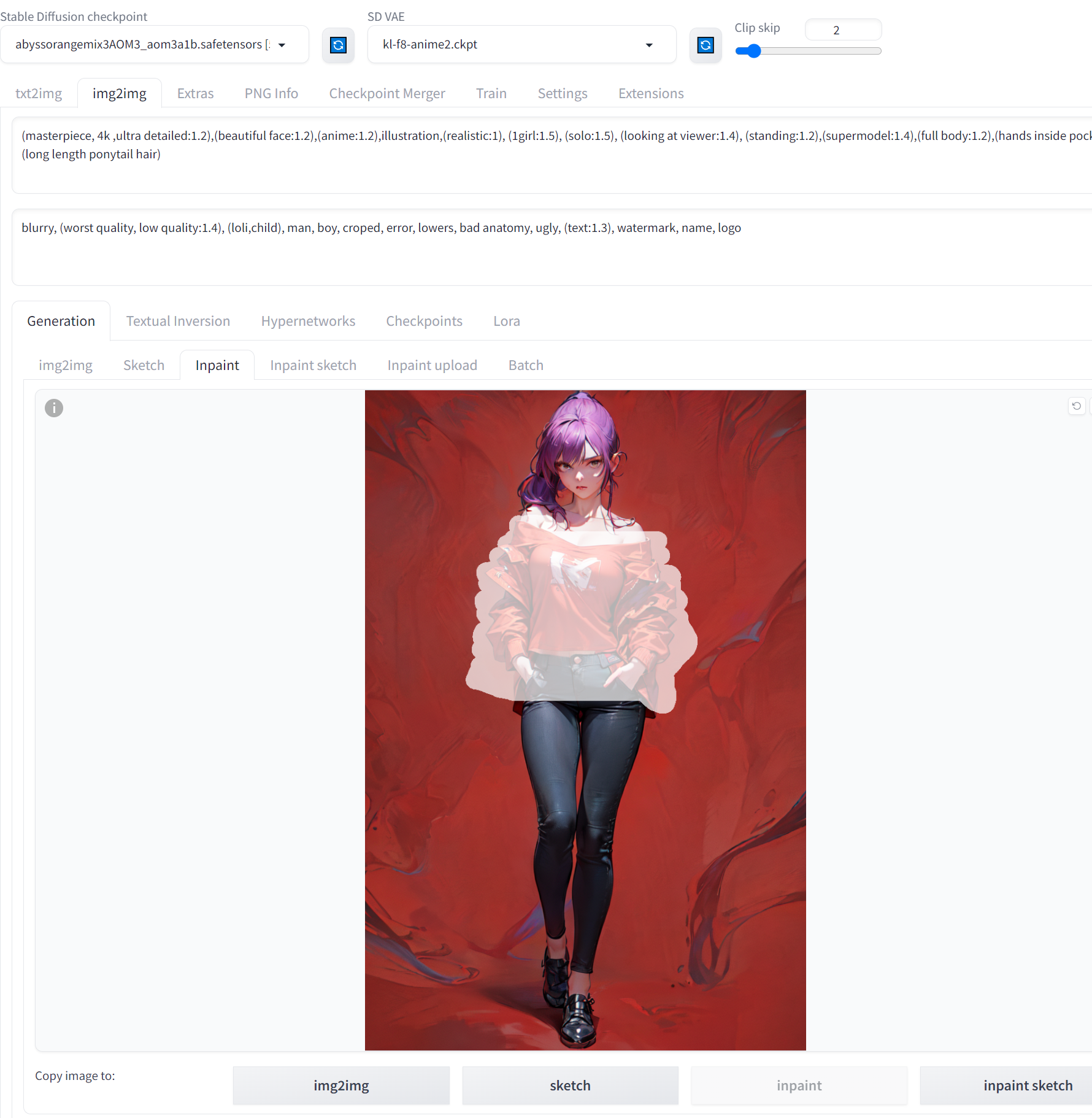
의상이나 특정부분을 바리에이션 칠때 좋은 기능같다.

카운트를 4로 올려서 생성

'기타 > AI 활용하기 기타' 카테고리의 다른 글
| 일상 생활속 미드저니 프롬프트 얻기 (여름, 구름 많음, 약간의 먹구름) (0) | 2024.06.23 |
|---|---|
| ChatGPT-4o 로 영상편집하기 (0) | 2024.05.26 |
| 스테이블 디퓨젼 사용기 5 (각 메뉴 심화2) (0) | 2024.03.14 |
| 스테이블 디퓨젼 사용기 3 (프롬프트 세팅) (0) | 2024.03.09 |
| 스테이블 디퓨젼 사용기 2 (0) | 2024.03.07 |